Orange Workflows
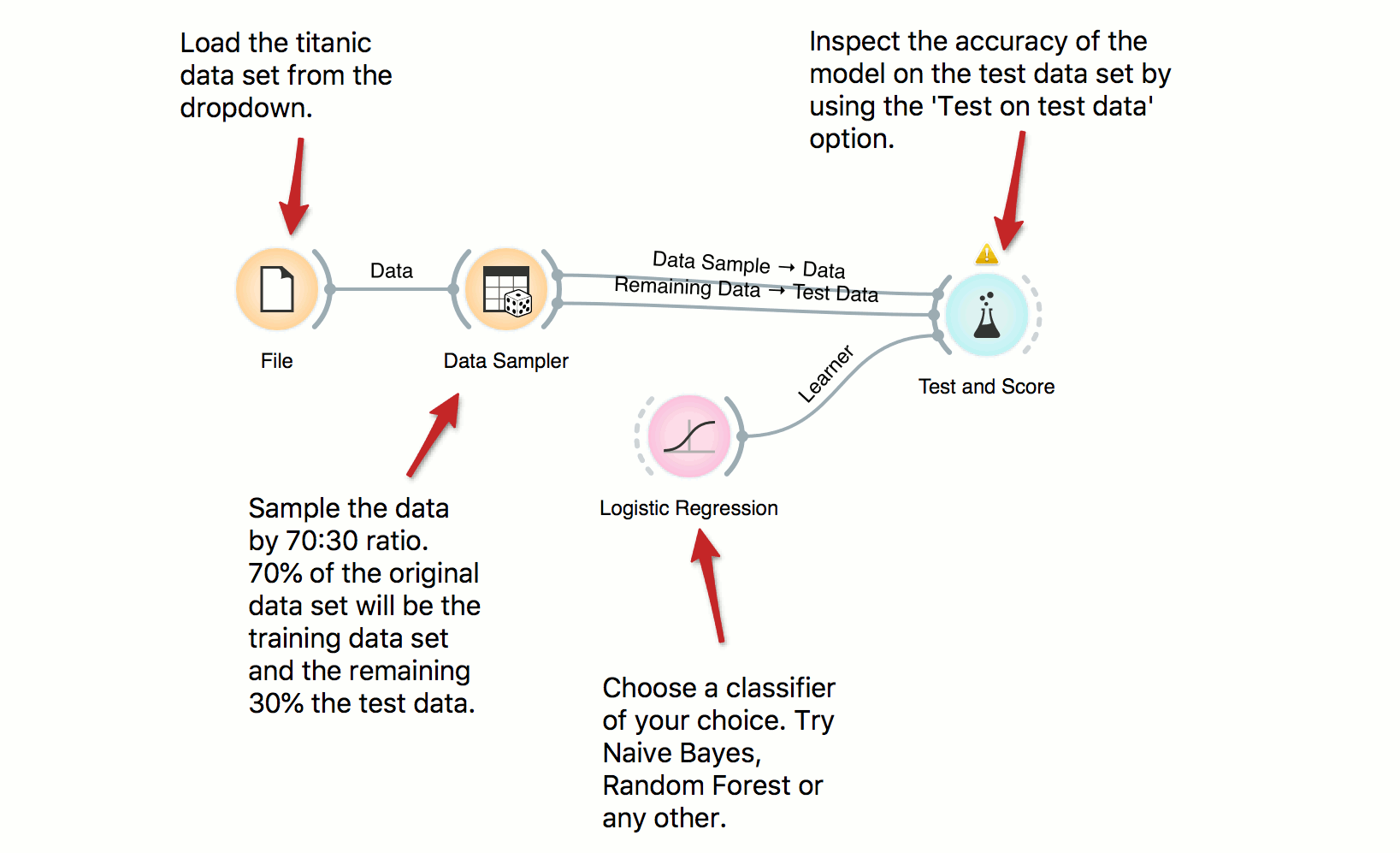
Train and Test Data
In building predictive models it is important to have a separate train and test data sets in order to avoid overfitting and to properly score the models. Here we use Data Sampler to split the data into training and test data, use training data for building a model and, finally, test on test data. Try several other classifiers to see how the scores change.
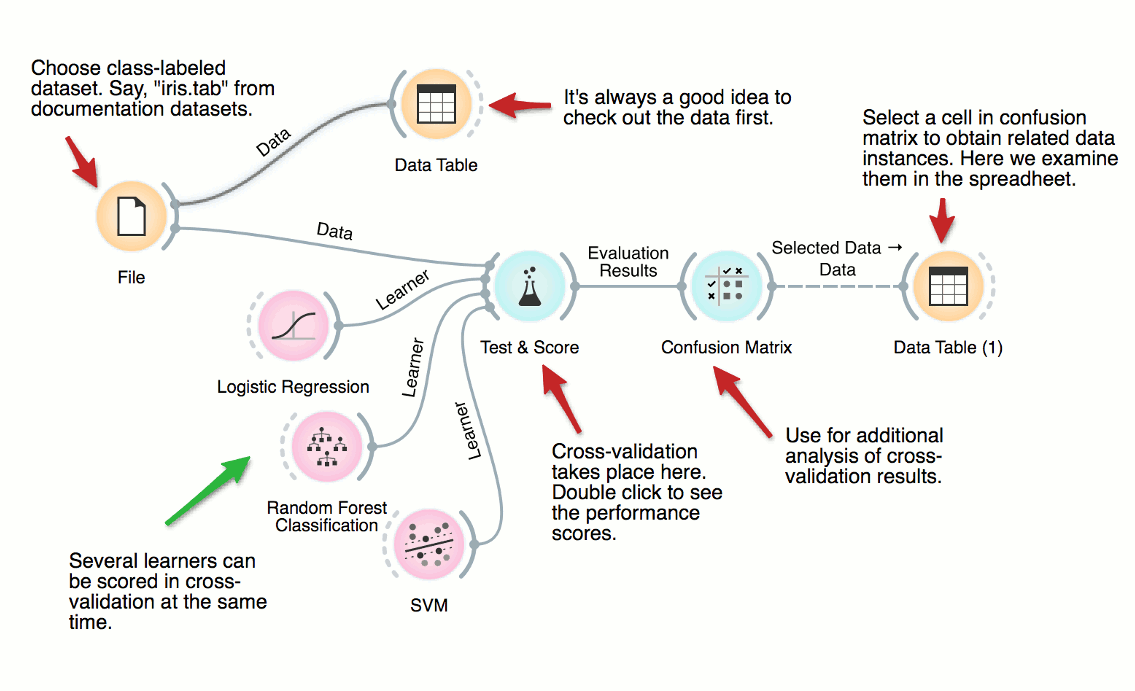
Cross Validation
How good are supervised data mining methods on your classification dataset? Here’s a workflow that scores various classification techniques on a dataset from medicine. The central widget here is the one for testing and scoring, which is given the data and a set of learners, does cross-validation and scores predictive accuracy, and outputs the scores for further examination.
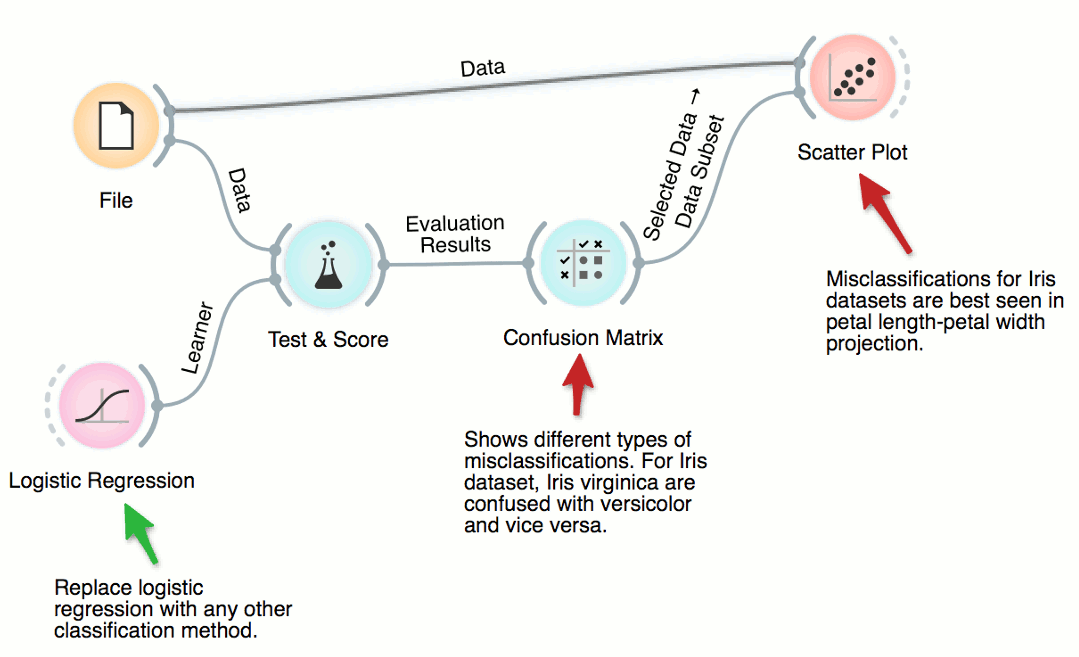
Where Are Misclassifications
Cross-validation of, say, logistic regression can expose the data instances which were misclassified. There are six such instances for iris dataset and ridge-regularized logistic regression. We can select different types of misclassification in Confusion Matrix and highlight them in the Scatter Plot. No surprise: the misclassified instances are close to the class-bordering regions in the scatter plot projection.
Text Preprocessing
Text mining requires careful preprocessing. Here’s a workflow that uses simple preprocessing for creating tokens from documents. First, it applies lowercase, then splits text into words, and finally, it removes frequent stopwords. Preprocessing is language specific, so change the language to the language of texts where required. Results of preprocessing can be observe in a Word Cloud.
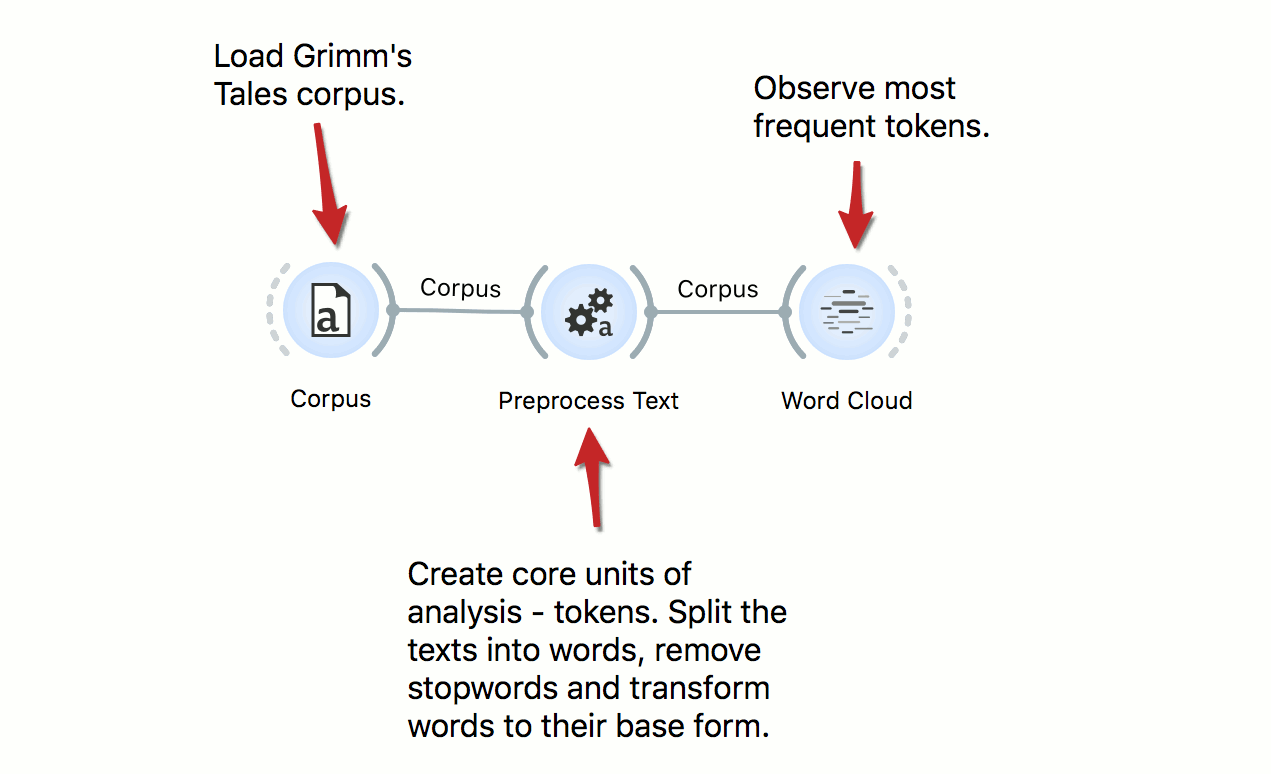
Text Clustering
The workflow clusters Grimm’s tales corpus. We start by preprocessing the data and constructing the bag of words matrix. Then we compute cosine distances between documents and use Hierarchical Clustering, which displays the dendrogram. We observe how well the type of the tale corresponds to the cluster in the MDS.
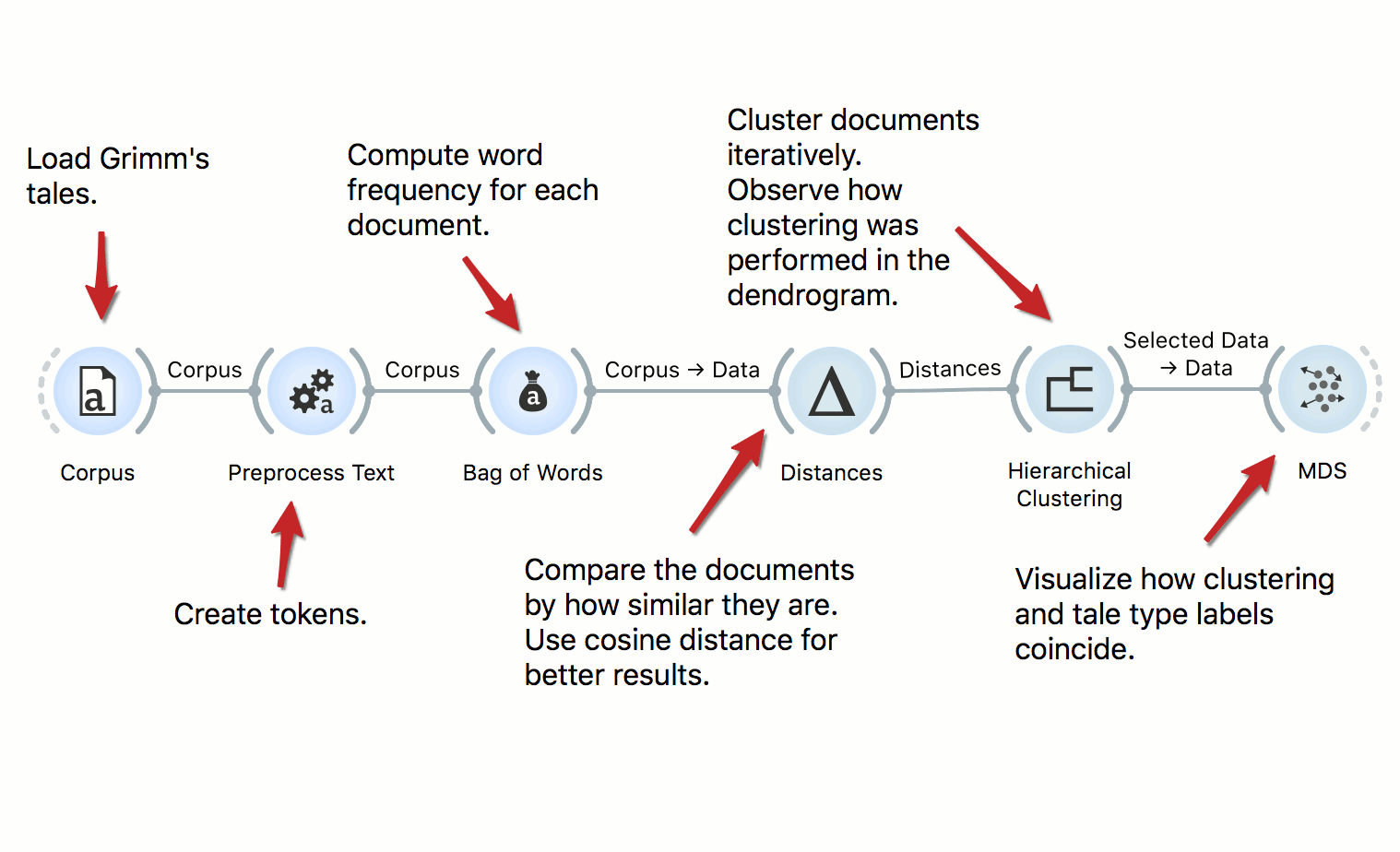
Text Classification
We can use predictive models to classify documents by authorship, their type, sentiment and so on. In this workflow we classify documents by their Aarne-Thompshon-Uther index, that is the defining topic of the tale. We use two simple learners, Logistic Regression and Naive Bayes, both of which can be inspected in the Nomogram.
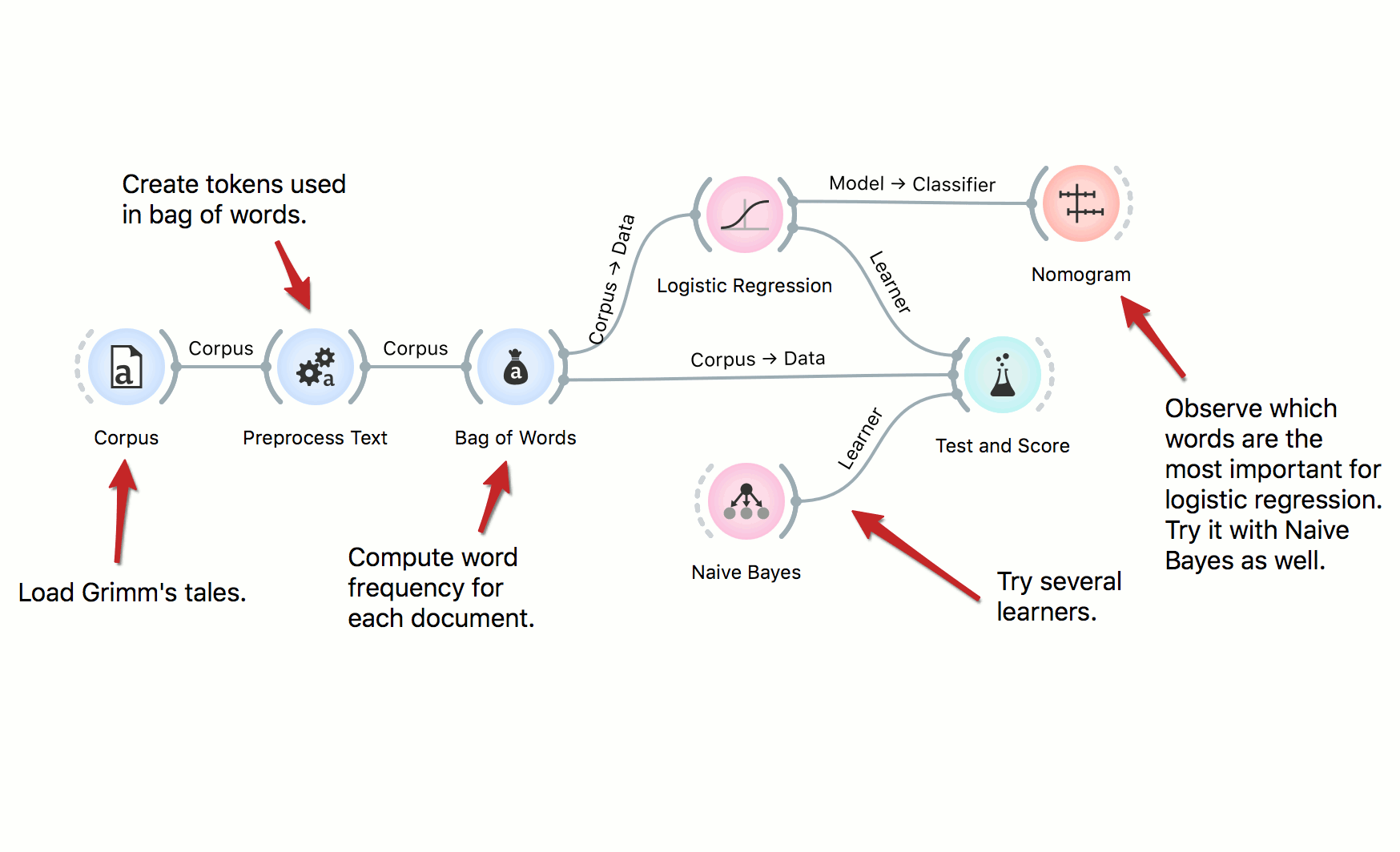
Twitter Data Analysis
Tweets are a valuable source of information, for social scientists, marketing managers, linguists, economists, and so on. In this workflow we retrieve data from Twitter, preprocess it, and uncover latent topics with topic modeling. We observe the topics in a Heat Map.
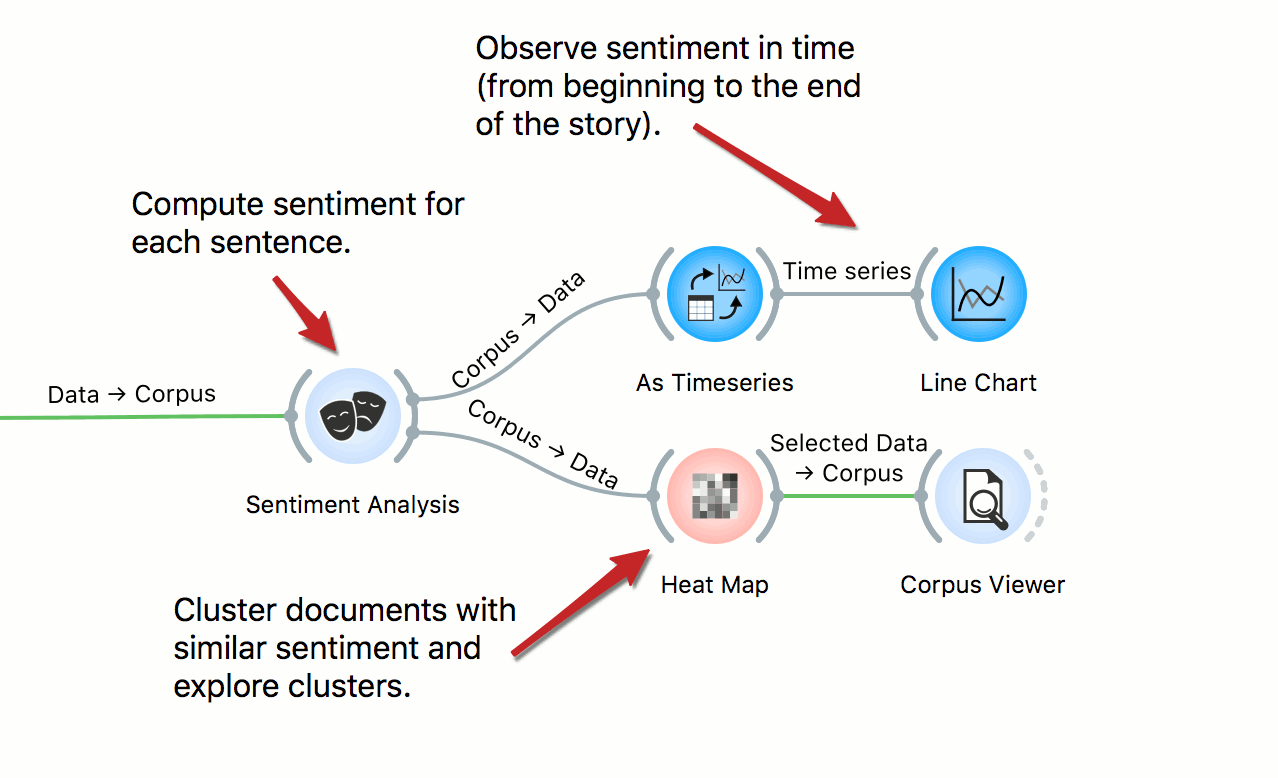
Story Arcs
In this workflow we explore story arcs in the Little Match Seller story. First we select the story from the corpus of Andersen tales. Then we create a table, where each sentence of the tale is a separate row. We use sentiment analysis to compute the sentiment of each sentence, then observe the emotional arcs through the story. We also inspect sentences with similar scores in the Heat Map and Corpus Viewer.
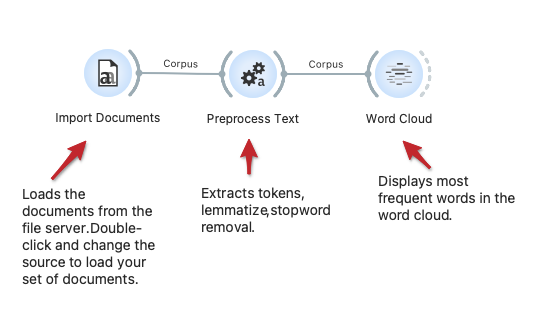
Load Text Corpus from the Server Repository
The workflow loads the corpus from the text repository on the server. The repository contains documents with raw text and associated YAML files with meta-features. We here use some pre-processing and then display the most frequent words in a word cloud. This workflow could work on your repository: just change the URL in the Import Documents widget.
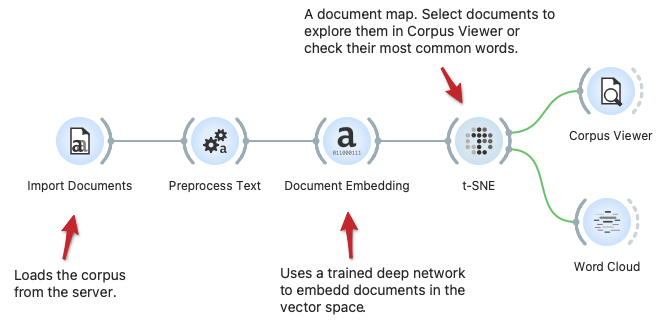
Semantic Document Map
Document maps may reveal clusters of documents with semantically similar content. Here we show a workflow that loads the corpus, performs some text preprocessing and embeds the documents in the vector space using the fastText deep model. The t-SNE widget reveals the document map, where we can select a set of documents and then explore them in Corpus Viewer or characterize them in the display of the most frequent words in the Word Cloud.