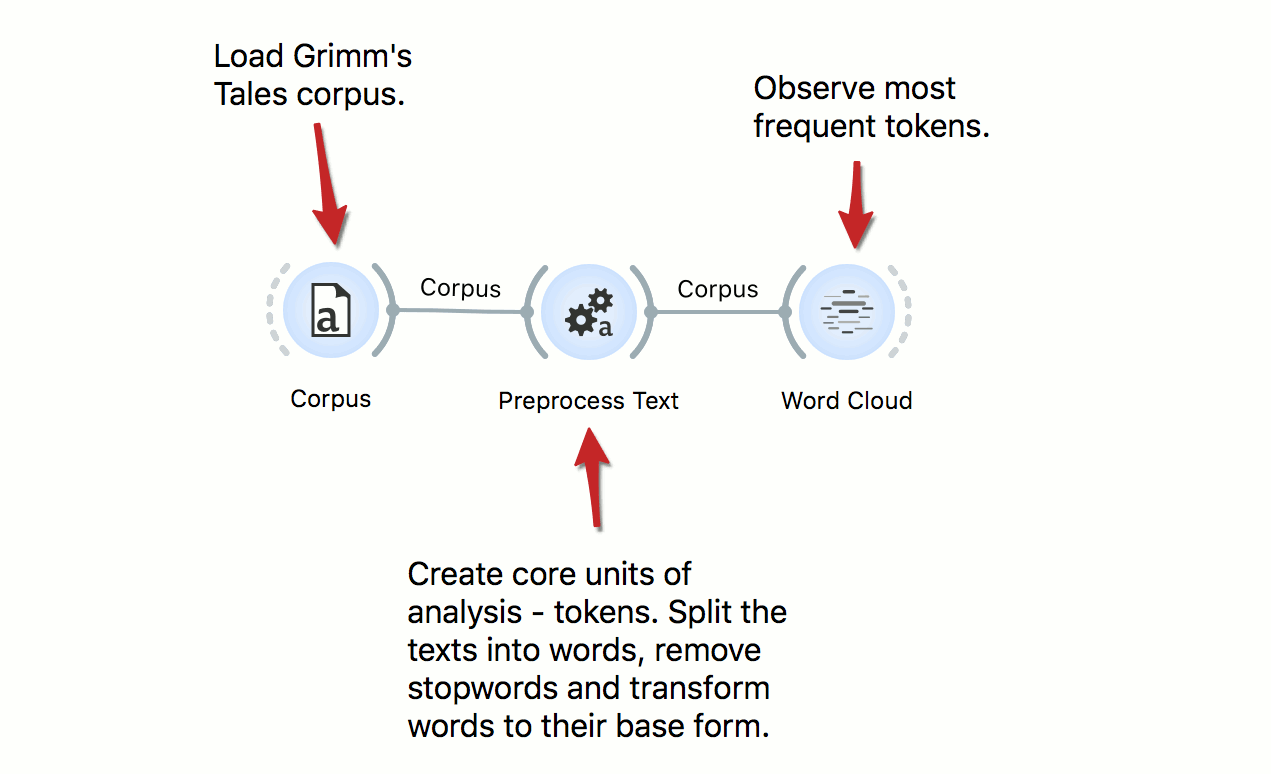
Orange Workflows
Text Preprocessing
Text mining requires careful preprocessing. Here’s a workflow that uses simple preprocessing for creating tokens from documents. First, it applies lowercase, then splits text into words, and finally, it removes frequent stopwords. Preprocessing is language specific, so change the language to the language of texts where required. Results of preprocessing can be observe in a Word Cloud.