Orange Workflows
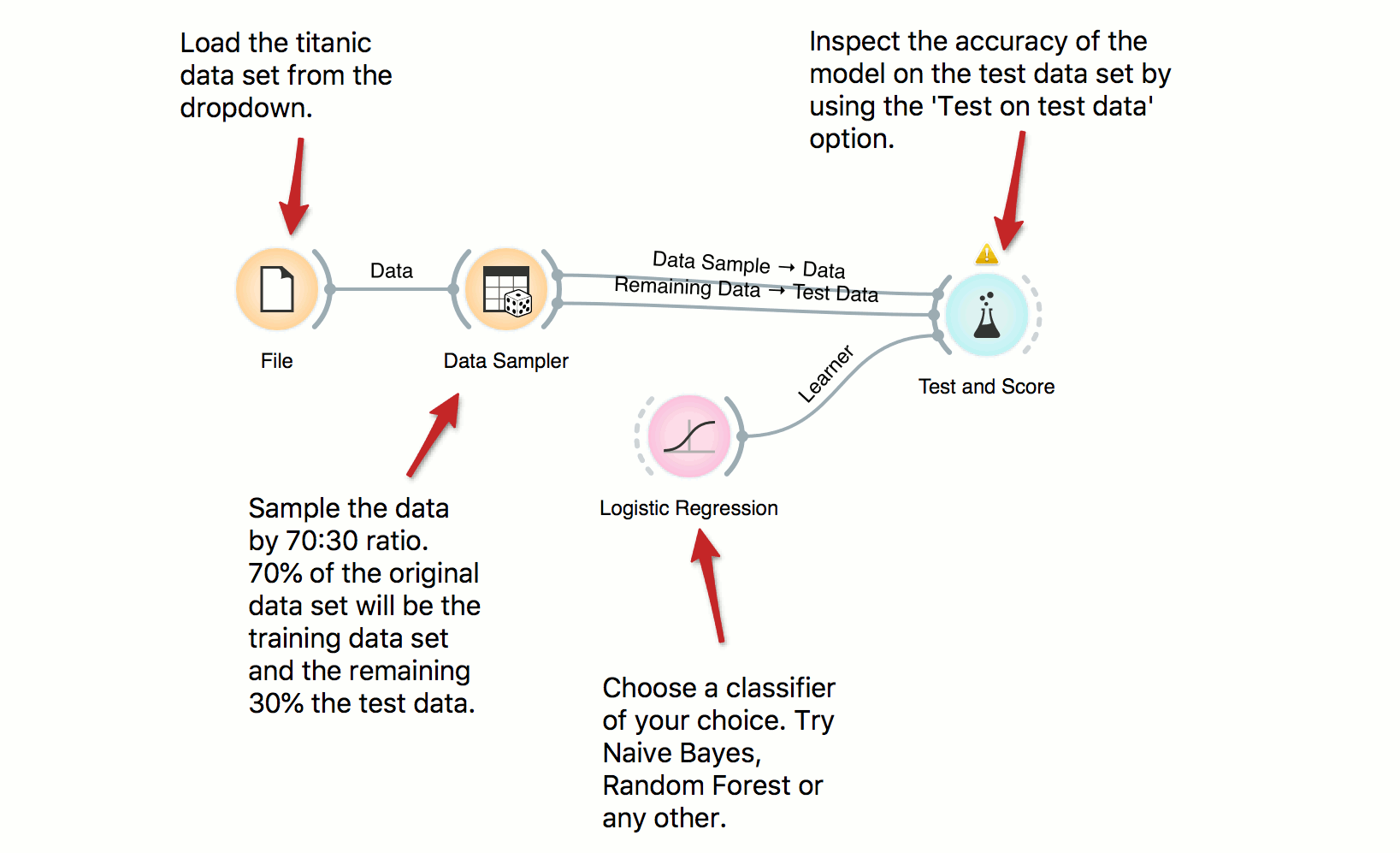
Train and Test Data
In building predictive models it is important to have a separate train and test data sets in order to avoid overfitting and to properly score the models. Here we use Data Sampler to split the data into training and test data, use training data for building a model and, finally, test on test data. Try several other classifiers to see how the scores change.
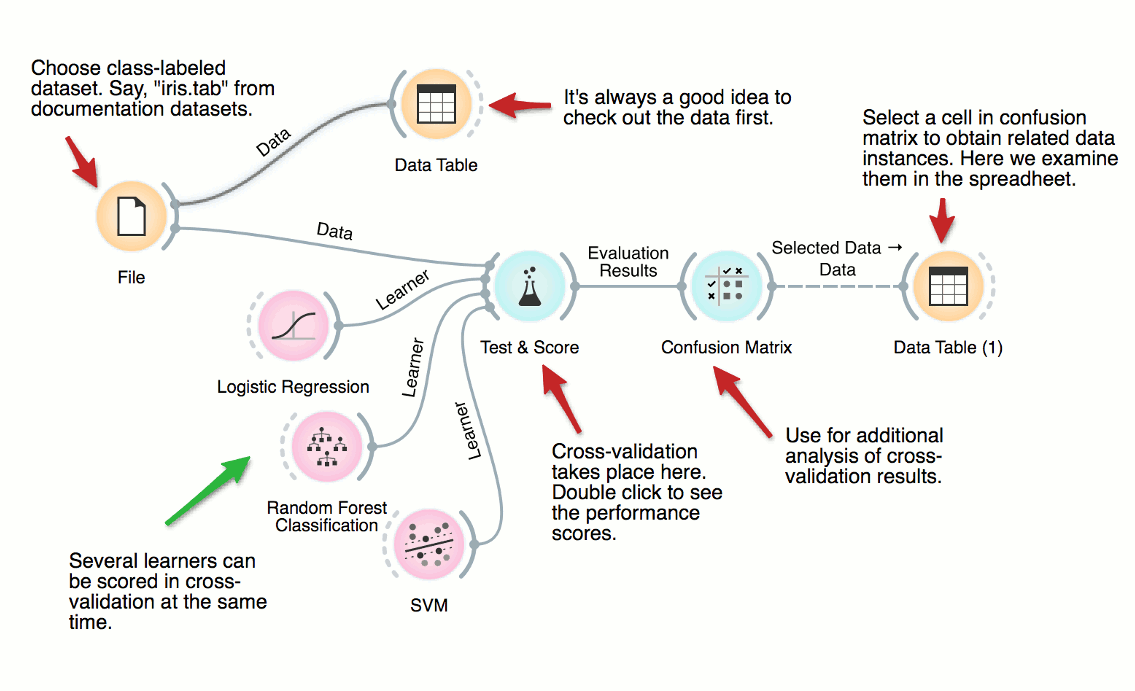
Cross Validation
How good are supervised data mining methods on your classification dataset? Here’s a workflow that scores various classification techniques on a dataset from medicine. The central widget here is the one for testing and scoring, which is given the data and a set of learners, does cross-validation and scores predictive accuracy, and outputs the scores for further examination.