Orange Workflows
Text Classification
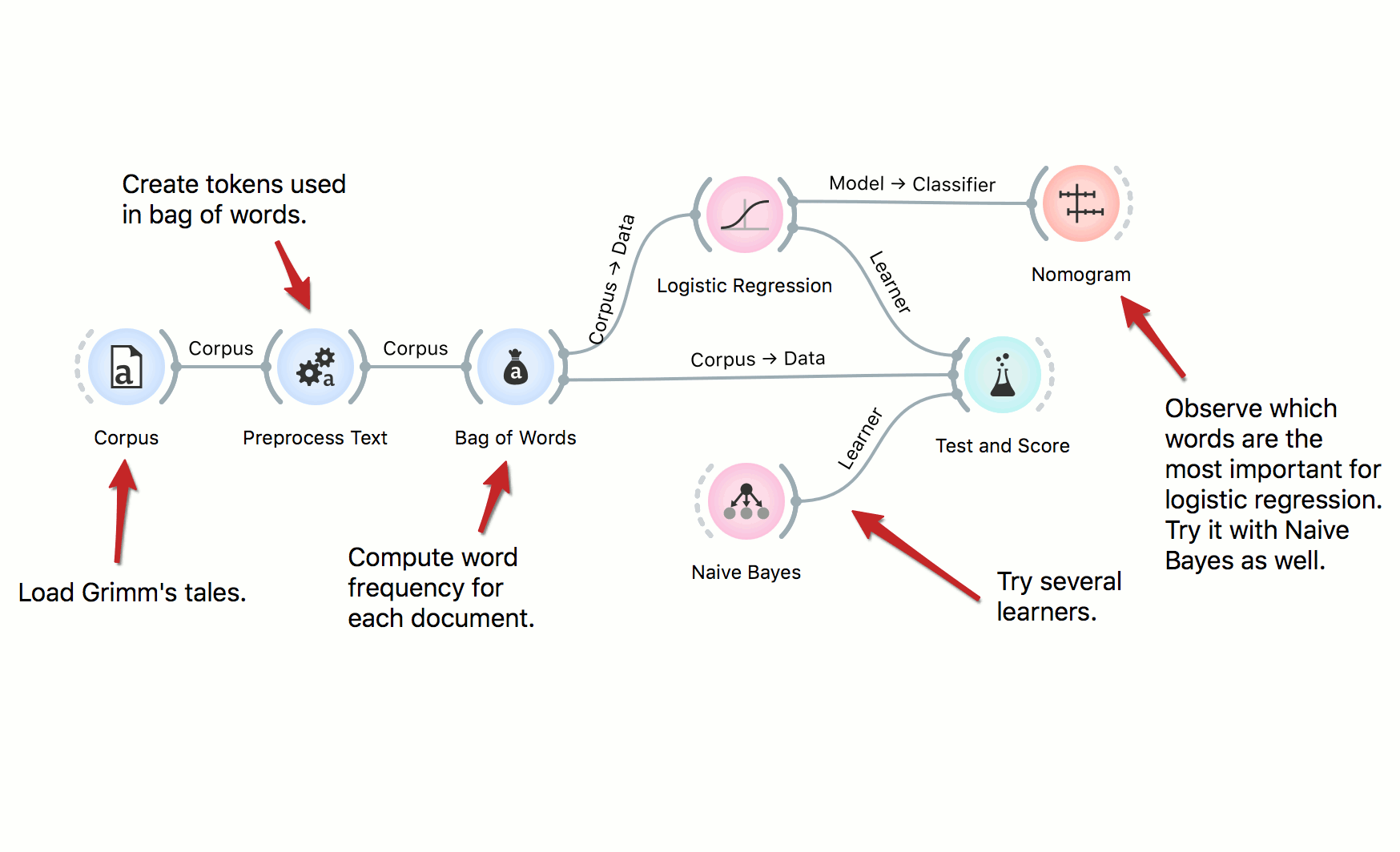
We can use predictive models to classify documents by authorship, their type, sentiment and so on. In this workflow we classify documents by their Aarne-Thompshon-Uther index, that is the defining topic of the tale. We use two simple learners, Logistic Regression and Naive Bayes, both of which can be inspected in the Nomogram.