The core element of Orange’s image analysis is embedding images in the vector space. Last year, we upgraded the embedding server infrastructure, enabling around ten times faster image embedding.
We switched from an old cluster with a fixed number of workers for each embedding to a new infrastructure where workers turn on when needed. It means that when a user sends images to the embedder, it will turn on as many instances as required until processors’ cores are available. Inception-v3, VGG16, and VGG19 embedders also perform computation on GPU, making them even faster.
We also made some modifications in the implementation on Orange’s part, making embedding more reliable.
How does embedding work?
The Image Embedding widget gets the table with images’ metadata such as an image name, location and size, but they are not ready for analysis. Images are sent to the server to be embedded in a format understandable to machine learning algorithms. The server pushes images through a pre-trained deep neural network and returns the number vectors to the widget.
Deep neural networks are trained on various specific tasks. Inception v3, VGG16, VGG19 and SqueezeNet are trained to classify images into 1000 classes according to the object at the image. Painters are trained to predict paintings’ authors, DeepLoc to predict yeast’s cells structures and OpenFace for face recognition. We disregard the classification layer of the network and consider the penultimate layer instead and use that for the image’s vector-based representation.
Editing photo collection
I have taken many photographs in the last few years, but I have not had the time to edit the collection. I want to sort them into subfolders based on the categories. Can machine learning algorithms and image embeddings help me with that?
This blog post will show two approaches for identifying categories and sorting images. The first one is unsupervised, and the second one is supervised.
First, we load photos. We load a folder of images with a collection that we would like to sort in the subfolders (download dataset).
Both approaches will include embedding images. We connect the Image Embedding widget to the Import Images widget to embed pictures and select Inception v3 embedder.
Our server deletes all images immediately after embedding. If you would not like to share your photos with our server anyway, you can select the SqueezeNet embedder that embeds images at your computer.
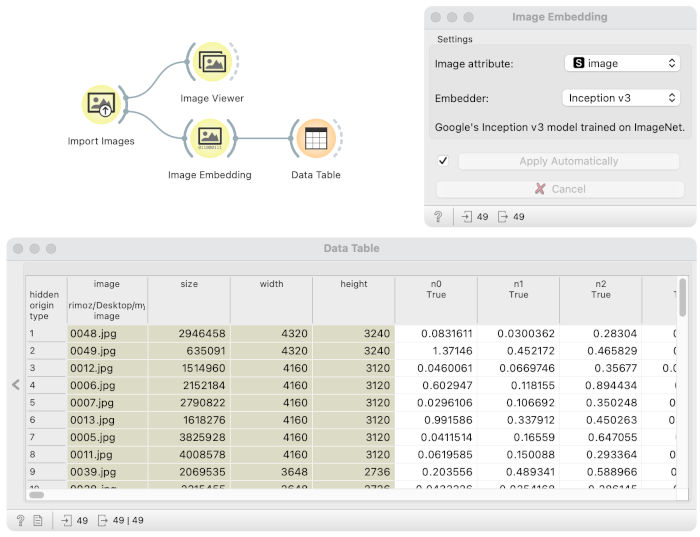
The Image Embedding widget added 2048 columns with numbers to each image in the data table. Those numbers describe properties that neural networks inferred from pictures. Numbers are not understandable to humans but make sense to machine learning algorithms.
Image grid will place similar photographs closer on the grid
The Image Grid uses t-sne embedding to project images on 2-dimensional plane based on their image embeddings. More similar images will be closer in the plot.
We passed embedded images from the Image Embedding to the Image Grid widget.
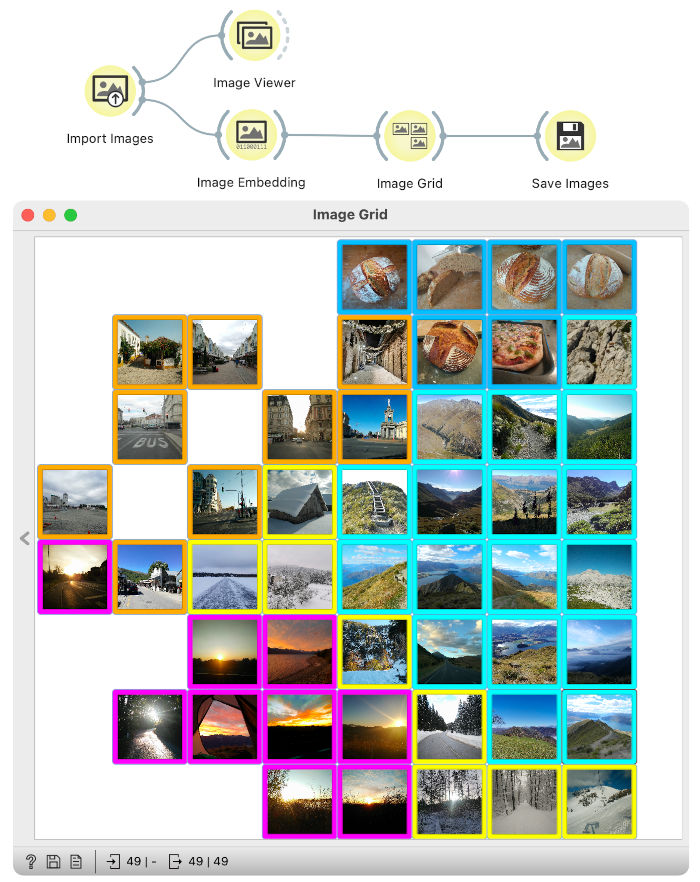
Image Grid has placed similar images closer in the grid. For example, in the top right corner are images of food, in the top left corner are photos of cities, on the right side are pictures of mountains, and at the bottom left are images of sunsets. The Image Grid had more difficulties with snowy photos. Some are placed at the bottom (they seem to include some mountain image elements), and three central ones seem to have elements of cities, mountains and snow.
Since images that belong to the same group are close together, it is easy to mark groups of images manually (colours around images). Marked groups are in the output table as class attributes. We can save them on the computer such that each group is a separate folder with the Save Images widget.
Related: Image Analytics: Clustering
Training the model to sort images
The Image Grid is excellent to discover similar images. Still, it is not practical to sort photos into category groups. If we would like to do that more often, we would always need to assign images to groups manually. Can we have a pipeline that would allow us to make a model that we can reuse later when we take new photos s?
Related: Video on image classification
We can train a classification model that will mark images with categories.
We prepared a separate training dataset with pictures in 5 subfolders. Folders are named: city, food, mountains, sunsets and winter. Names of the folders define categories; once the model is trained, it will always classify images in those categories.
We will first test how accurate the model is.
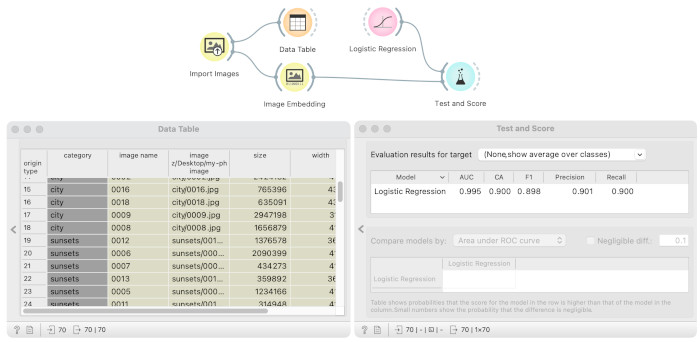
The Import Images widget loads images from the training dataset (download the training data). Since images are sorted in multiple folders, the widget assigns the folder name to images as a category, which we can see in the Data Table. We embed images with Inception v3 embedder in the Image Embedding widget and performs cross-validation in the Test and Score widget. The model we use is logistic regression. We are happy with the model with AUC 0.992 and classification accuracy of 0.943.
Now we can train the model that will be used to label an unlabeled set of photos.
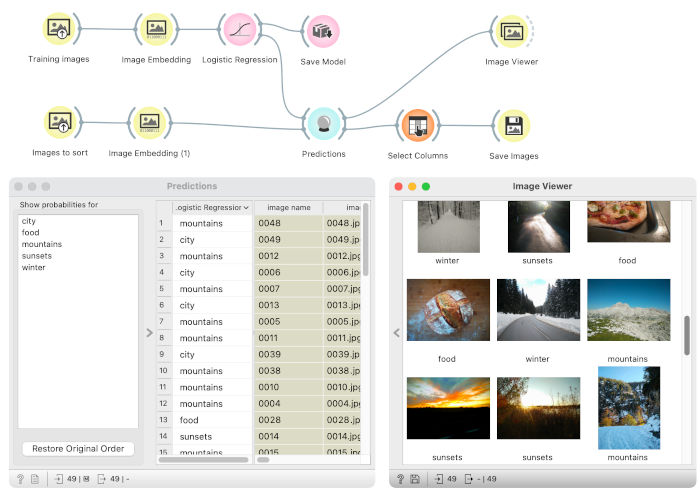
We train the logistic regression model on the training images in the top branch on the labelled training dataset. Data that we want to label (sort in subfolders) are loaded and embedded in the bottom branch. We use the same images as in the first part of the blog. The Predictions widget assigns labels to the images based on the logistic regression model.
We use the Image Viewer to inspect assigned labels to images. Labels seem to be meaningful and correct. Now that we have photos labelled, we save them to the folder structure with the Save Images widget such that each folder is one category. Since the Prediction widget places predictions (column named Logistic Regression) in the meta part of the table, we need to first set the attribute as a target with the Select Columns widget — the Save Images widget uses the target column as a subfolder name.
We also connected the Save Model widget to the Logistic Regression. This way, the model is saved for later and can be reused.
Want to learn more?
We showed two ways of analysing images with Orange’s Image Analytics module. The Image Grid is a great tool to identify similar images and see them in the grid. The second one needs an extra effort to prepare a training dataset, but this leads to an automatic pipeline to identify categories.
If you want to learn more about Image Analysis in Orange watch the tutorial wideos or read related blogs: Image Analytics: Clustering, Clustering of Monet and Manet, and Outliers in Traffic Signs