For the second year in a row, the Orange team was a part of the Ljubljana Doctoral Summer School, which is organized by the School of Economics and Business, University of Ljubljana. Our course, called Pratical Introduction to Machine Learning and Data Analytics, was aimed at presenting the nuts and bolts of data science methods and concepts with the help of visual programming. In Orange, of course.

\
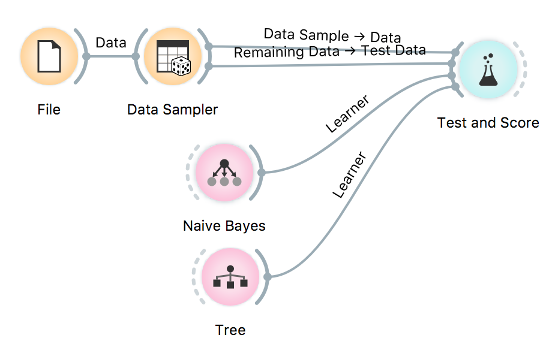
One important lesson is comparing model accuracy. Let us load the heart_disease data with the File widget. This is the data on the presence of diameter narrowing (a sign of heart disease) in 303 patients. Now let us sample the data into the training and testing data. We will use Data Sampler for this.
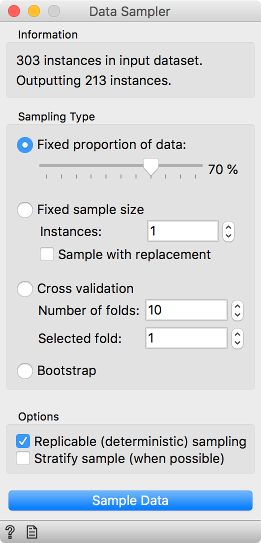
\
Now let’s check model accuracy on, say, Tree and Naive Bayes, one of the first two classifiers that we introduce. Connect both outputs of Data Sampler to Test & Score, the first as Data and the second as Test Data.
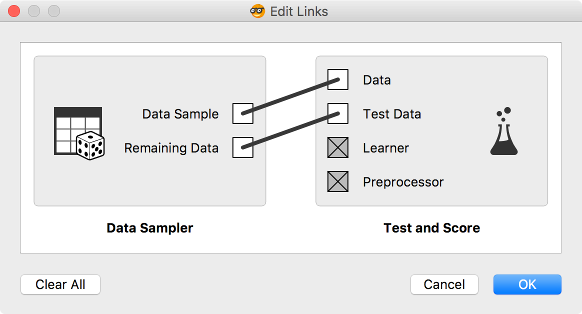
\
First, check the model accuracy with the Test on train data option. Great scores! Seems like Tree performs almost flawlessly. It must be the better classifier of the two!
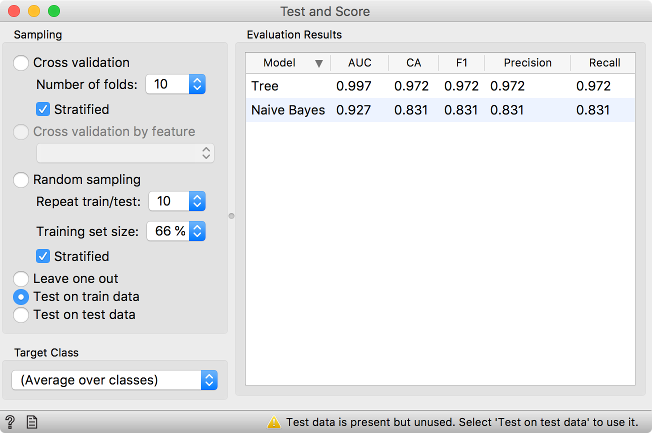
\
Ok, just to be sure, let us check the scores on a separate test data set by selecting Test on test data. Oh. This doesn’t look good. Tree now performs much worse than Naive Bayes. Why is that?
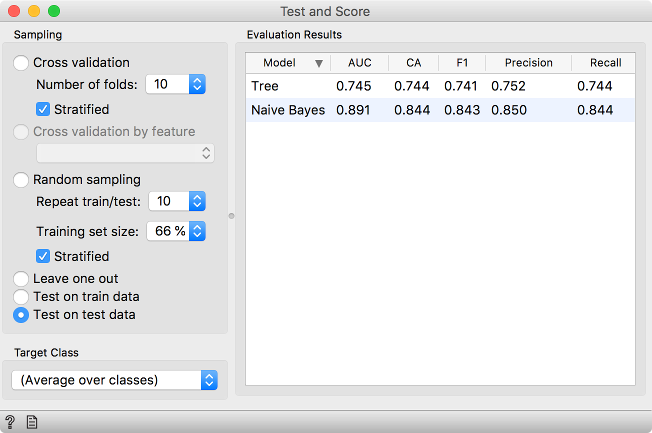
\
We won’t answer this directly, but this is one of the homeworks we give the students in order to introduce cross-validation. This is such an important concept that we make sure everyone in the class really understand why we need separate training and testing data.
Feel free to use this exercise in any of your future classes!