Every fall I teach a course on Introduction to Data Mining. And while the course is really on statistical learning and its applications, I also venture into classification trees. For several reasons. First, I can introduce information gain and with it feature scoring and ranking. Second, classification trees are one of the first machine learning approaches co-invented by engineers (Ross Quinlan) and statisticians (Leo Breiman, Jerome Friedman, Charles J. Stone, Richard A. Olshen). And finally, because they make the base of random forests, one of the most accurate machine learning models for smaller and mid-size data sets.
Related: Introduction to Data Mining Course in Houston
Lecture on classification trees has to start with the data. Years back I have crafted a data set on sailing. Every data set has to have a story. Here is one:
Sara likes weekend sailing. Though, not under any condition. Past twenty Wednesdays I have asked her if she will have any company, what kind of boat she can rent, and I have checked the weather forecast. Then, on Saturday, I wrote down if she actually went to the Sea.
Data on Sara’s sailing contains three attributes (Outlook, Company, Sailboat) and a class (Sail).
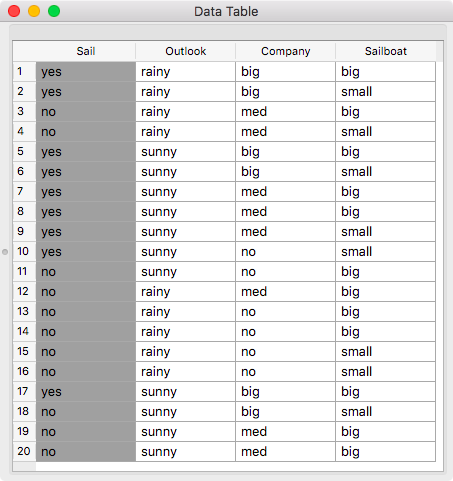
The data comes with Orange and you can get them from Data Sets widget (currently in Prototypes Add-On, but soon to be moved to core Orange). It takes time, usually two lecture hours, to go through probabilities, entropy and information gain, but at the end, the data analysis workflow we develop with students looks something like this:
And here is the classification tree:
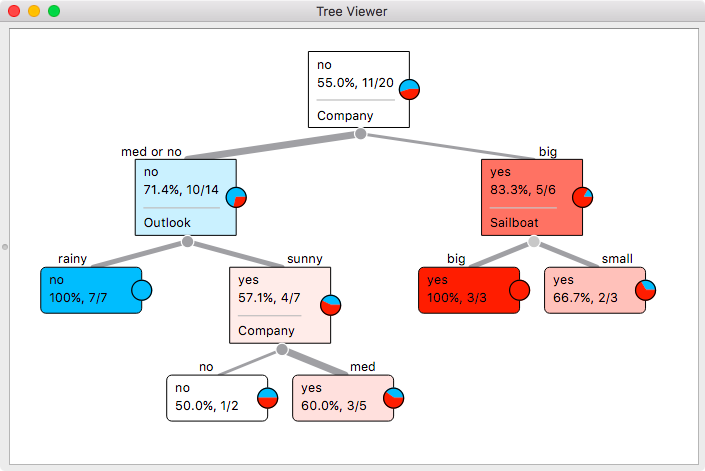
Turns out that Sara is a social person. When the company is big, she goes sailing no matter what. When the company is smaller, she would not go sailing if the weather is bad. But when it is sunny, sailing is fun, even when being alone.
Related: Pythagorean Trees and Forests
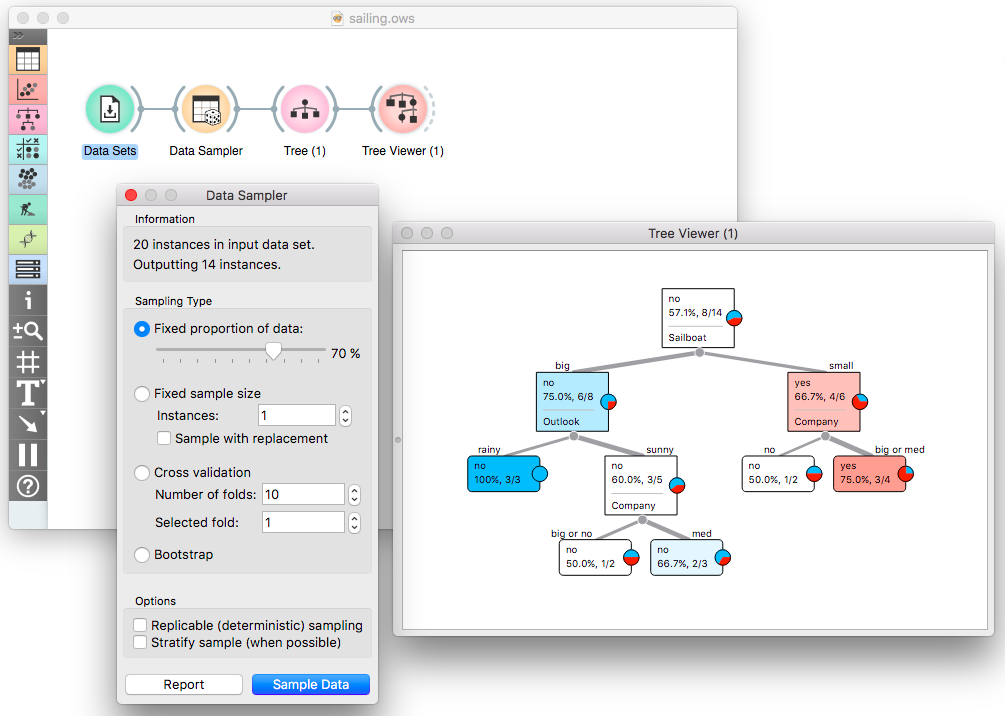
Classification trees are not very stable classifiers. Even with small changes in the data, the trees can change substantially. This is an important concept that leads to the use of ensembles like random forests. It is also here, during my lecture, that I need to demonstrate this instability. I use Data Sampler and show a classification tree under the current sampling. Pressing on Sample Data button the tree changes every time. The workflow I use is below, but if you really want to see this in action, well, try it in Orange.