February was a month of Orange workshops.
Ljubljana: Biologists

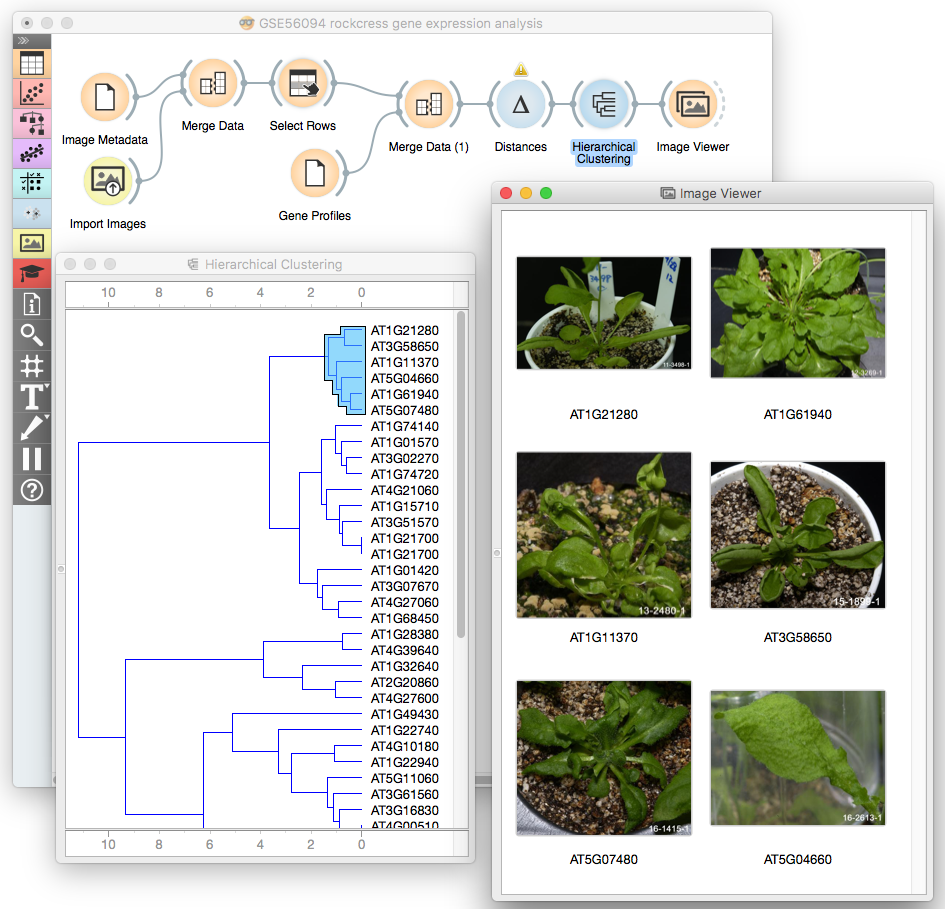
We (Tomaž, Martin and I) have started in Ljubljana with a hands-on course for the COST Action FA1405 Systems Biology Training School. This was a four hour workshop with an introduction to classification and clustering, and then with application of machine learning to analysis of gene expression data on a plant called Arabidopsis. The organization of this course has even inspired us for a creation of a new widget GOMapMan Ontology that was added to Bioinformatics add-on. We have also experimented with workflows that combine gene expressions and images of mutant. The idea was to find genes with similar expression profile, and then show images of the plants for which these genes have stood out.
Luxembourg: Statisticians

This workshop took place at STATEC, Luxembourgh’s National Institute of Statistics and Economic Studies. We (Anže and I) got invited by Nico Weydert, STATEC’s deputy director, and gave a two day lecture on machine learning and data mining to a room full of experienced statisticians. While the purpose was to showcase Orange as a tool for machine learning, we have learned a lot from participants of the course: the focus of machine learning is still different from that of classical statistics.
Statisticians at STATEC, like all other statisticians, I guess, value, above all, understanding of the data, where accuracy of the models does not count if it cannot be explained. Machine learning often sacrifices understanding for accuracy. With focus on data and model visualization, Orange positions itself somewhere in between, but after our Luxembourg visit we are already planning on new widgets for explanation of predictions.
Pavia: Engineers

About fifty engineers of all kinds at University of Pavia. Few undergrads, then mostly graduate students, some postdocs and even quite a few of the faculty staff have joined this two day course. It was a bit lighter that the one in Luxembourg, but also covered essentials of machine learning: data management, visualization and classification with quite some emphasis on overfitting on the first day, and then clustering and data projection on the second day. We finished with a showcase on image embedding and analysis. I have in particular enjoyed this last part of the workshop, where attendees were asked to grab a set of images and use Orange to find if they can cluster or classify them correctly. They were all kinds of images that they have gathered, like flowers, racing cars, guitars, photos from nature, you name it, and it was great to find that deep learning networks can be such good embedders, as most students found that machine learning on their image sets works surprisingly well.
Related: BDTN 2016 Workshop on introduction to data science
Related: Data mining course at Baylor College of Medicine
We thank Riccardo Bellazzi, an organizer of Pavia course, for inviting us. Oh, yeah, the pizza at Rossopommodoro was great as always, though Michella’s pasta al pesto e piselli back at Riccardo’s home was even better.