One of the key questions of every data analysis is how to get the data and put it in the right form(at). In this post I’ll show you how to easily get the data from the web and transfer it to a file Orange can read.
Related: Creating a new data table in Orange through Python
First, we’ll have to do some scripting. We’ll use a couple of Python libraries - urllib.requests fetching the data, BeautifulSoup for reading it, csv for writing it and regular expressions for extracting the right data.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
import re
Ok, we’ve imported the all the libraries we’ll need. Now we will scrape the data from our own blog to see how many posts we’ve written throughout the years.
html = urlopen('http://blog.biolab.si')
soup = BeautifulSoup(html.read(), 'lxml')
The first line opens the address of the site we want to scrape. In our case this is our blog. The second line retrieves a html response from the site, which is our raw text. It looks like this:
<aside id="archives-2" class="widget widget_archive"><h3 class="widget-title">Archives</h3>
<ul>
<li><a href='http://blog.biolab.si/2017/01/'>January 2017</a> (1)</li>
<li><a href='http://blog.biolab.si/2016/12/'>December 2016</a> (3)</li>
<li><a href='http://blog.biolab.si/2016/11/'>November 2016</a> (4)</li>
<li><a href='http://blog.biolab.si/2016/10/'>October 2016</a> (3)</li>
<li><a href='http://blog.biolab.si/2016/09/'>September 2016</a> (2)</li>
<li><a href='http://blog.biolab.si/2016/08/'>August 2016</a> (5)</li>
<li><a href='http://blog.biolab.si/2016/07/'>July 2016</a> (3)</li>....
Ok, html is nice, but we can’t really do data analysis with this. We will have to transform this output into something sensible. How about .csv, a simple comma-demilited format Orange can recognize?
with open('scraped.csv', 'w') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',')
We created a new file called ‘scraped.csv’ to which we will write our content (‘w’ parameter means write). Then we defined the writer and set the delimiter to comma.
Now we need to add the header row, so Orange will know what are the column names. We add this just after csvwriter variable.
csvwriter.writerow(["Date", "No_of_Blogs"])
Now we have two columns, one named ‘Date’ and the other ‘No_of_Blogs’. The final step is to extract the data. We have a bunch of lines in html, but the one we’re interested in is in a section ‘aside’ and has an id ‘archives-2’. We will first extract only this section (.find(id=‘archives-2’) and get all the lines of the archive with the tag ’li’ (.find_all(’li’)):
for item in soup.find(id="archives-2").find_all('li'):
This is the result of print(item).
<li><a href="http://blog.biolab.si/2017/01/">January 2017</a> (1)</li>
Now we need to get the actual content from each line. The first part we need is the date of the archived content. Orange can read dates, but they need to come in the right format. We will extract the date from href part with item.a.get(‘href’). Then we need to extract only digits from it as we’re not interested in the rest of the link. We do this with Regex for finding digits:
date = re.findall(r'\d+', item.a.get('href'))
Regex’s findall function returns a list, in our case containing two items - the year and month of archived content. The second part of our data is the number of blogs archived in a particular month. We will again extract this with a Regex digit search, but this time we will be extracting data from the actual content - ‘item.contents[1]’.
digits = re.findall(r'\d+', item.contents[1])
Finally, we need to write each line to a .csv file we created above.
csvwriter.writerow(["%s-%s-01" % (date[0], date[1]), digits[0]])
Here, we formatted the date into an ISO-standard format Orange recognizes as time variable ("%s-%s-01" % (date[0], date[1])), while the second part is simply a count of our blog posts.
This is the entire code:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import csv
import re
html = urlopen('http://blog.biolab.si')
soup = BeautifulSoup(html.read(), 'lxml')
with open('scraped.csv', 'w') as csvfile:
csvwriter = csv.writer(csvfile, delimiter=',')
csvwriter.writerow(["Date", "No_of_Blogs"])
for item in soup.find(id="archives-2").find_all('li'):
date = re.findall(r'\d+', item.a.get('href'))
digits = re.findall(r'\d+', item.contents[1])
csvwriter.writerow(["%s-%s-01" % (date[0], date[1]), digits[0]])
Related: Scripting with Time Variable
Now let’s load this in Orange. File widget can easily read .csv formats and also correctly identifies the two column types, datetime and numeric. A quick glance into the Data Table…
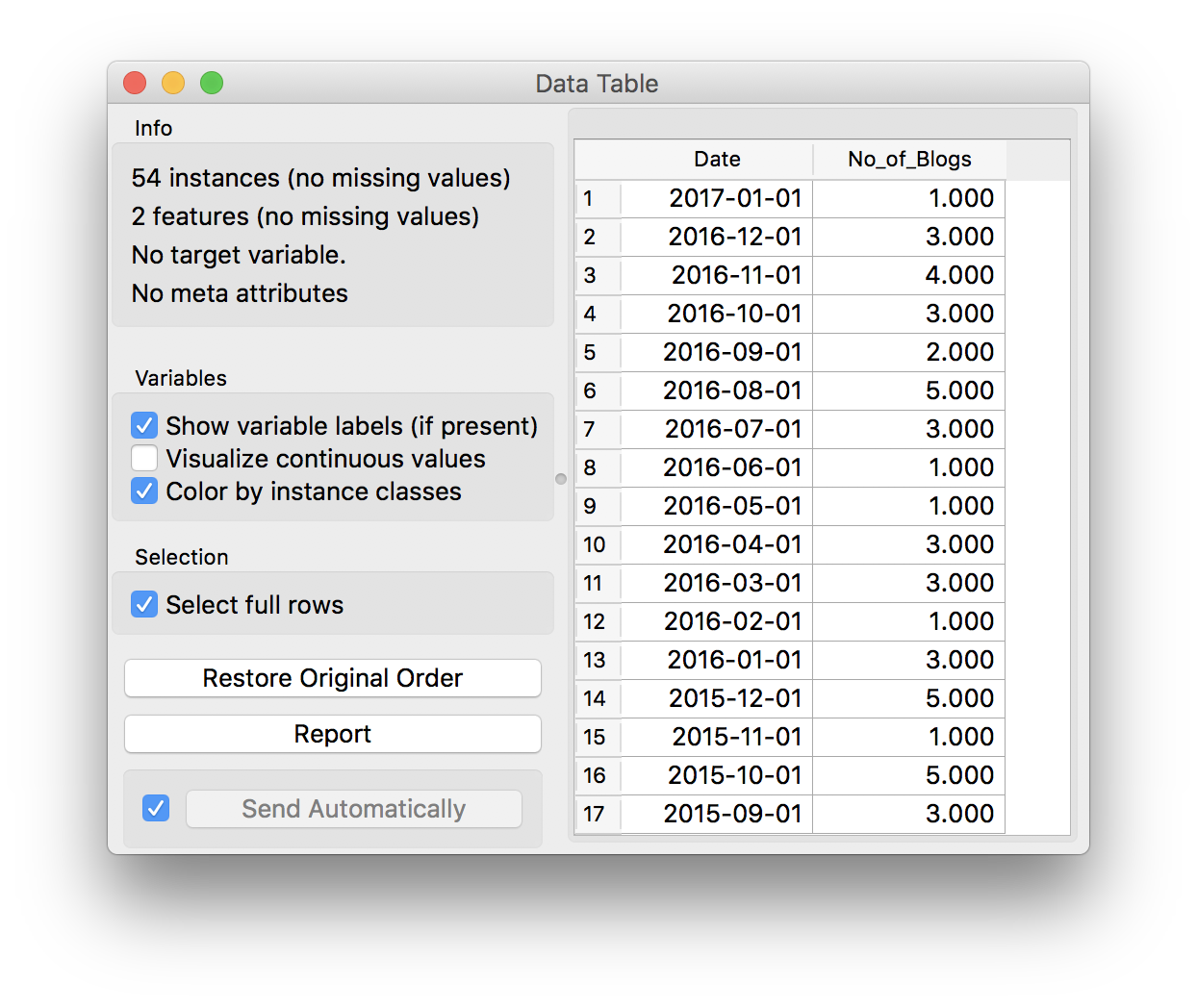
Everything looks ok. We can use Timeseries add-on to inspect how many blogs we’ve written each month since 2010. Connect As Timeseries widget to File. Orange will automatically suggest to use Date as our time variable. Finally, we’ll plot the data with Line Chart. This is the curve of our blog activity.
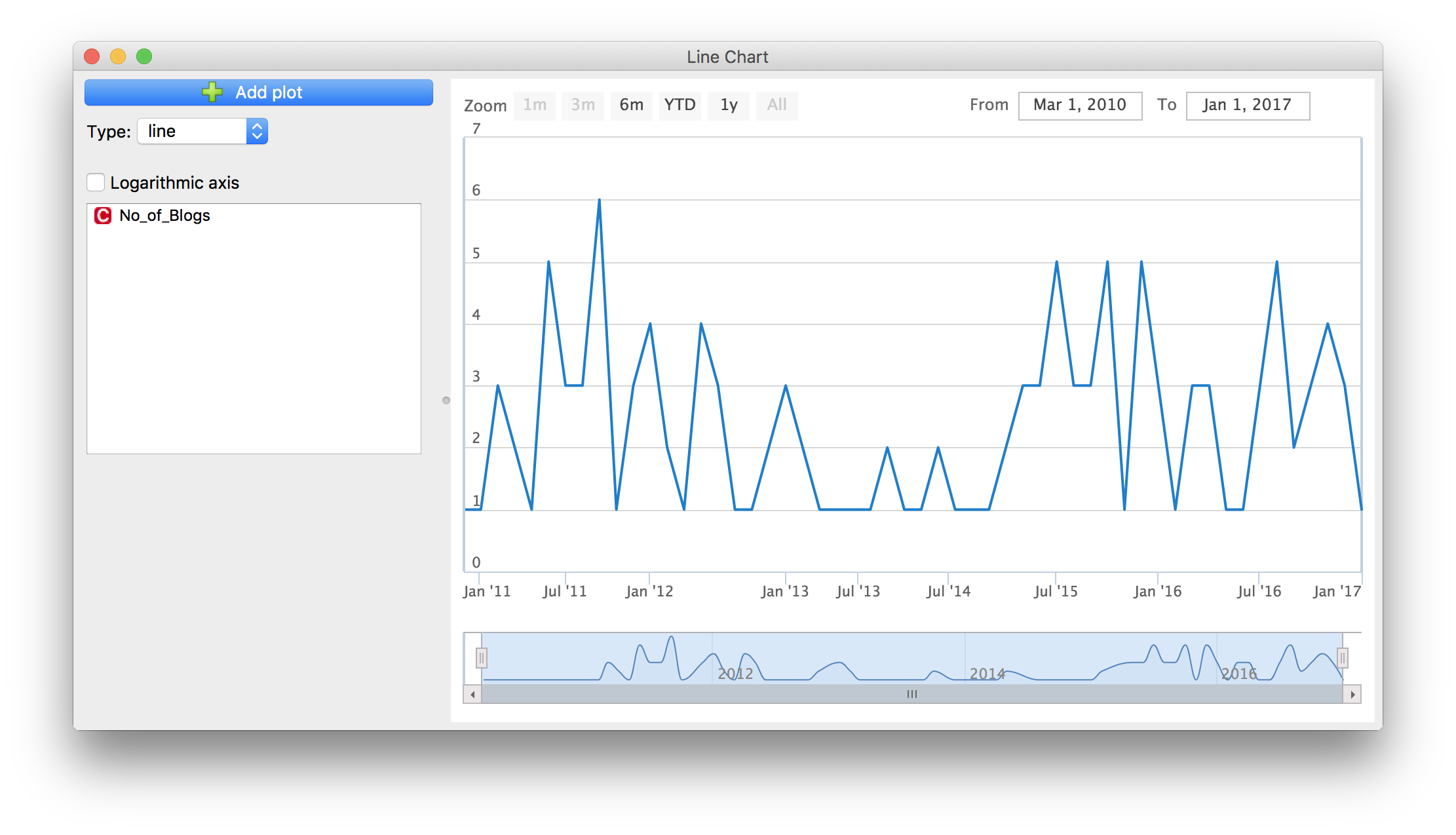
The example is extremely simple. A somewhat proficient user can extract much more interesting data than a simple blog count, but one always needs to keep in mind the legal aspects of web scraping. Nevertheless, this is a popular and fruitful way to extract and explore the data!